理解Parquet存储格式
Parquet格式是目前大数据存储的de facto standard。本文从非工程师的视角对Parquet做一个比较全面详尽的介绍,尤其详细讲解了最容易产生误解的嵌套结构部分。
数据存储模型背景
N-ary Storage Model (NSM)
早期的数据库管理系统大多都是联机事务处理系统(OLTP),需要频繁插入和更新记录,所以通常使用行式存储(NSM,N-ary Storage Model)。NSM模式将多条记录连续存储在一个页中,在内存中对数据的读取和写入操作效率很高,能够快速完成插入密集型的工作负载。此外,由于每个页中的数据量较小(通常页大小为4KB),这种模式在需要快速访问具体记录的情况下表现尤为出色。
Decomposition Storage Model (DSM)
随着大规模分析任务的流行,联机分析处理系统(OLAP)对存储格式提出了新的需求,即高效读取大型数据集的指定列。DSM模式,也被称为列存储模式,是为OLAP工作负载设计的。在DSM中,DBMS将每个属性/列的所有数据连续存储在一个数据块中,这样在可以只访问表的指定列,而无需读取整个表。
Hybrid Storage Model (PAX)
PAX(Partition Attributes Across)是一种混合存储模型,它结合了行存储和列存储的优点。在PAX中,数据首先被水平分区为行组(row groups),然后在每个行组内按照列块(column chunks)存储。这样既保留了列存储在读取大量数据时的高效性,又保持了行存储中数据在空间上的临近。这种混合模型使得PAX能够兼顾存储效率和读取性能,适合复杂查询和大规模数据处理场景,在现代数据分析工作中广泛应用。Parquet和ORC格式都采用了PAX模型。
Parquet
开发背景
Parquet由Twitter和Cloudera合作开发,2013年7月启动,2015年5月从Apache的孵化器里毕业成为Apache顶级项目。Twitter的日增数据量达到压缩之后的100TB+,存储在HDFS上,工程师会使用多种计算框架(例如MapReduce, Hive, Pig等)对这些数据做分析和挖掘;日志结构是复杂的嵌套数据类型,例如一个典型的日志的schema有87列,嵌套了7层。所以需要设计一种列式存储格式,既能支持关系型数据(简单数据类型),又能支持复杂的嵌套类型的数据,同时能够适配多种数据处理框架。Parquet是语言无关的,而且不与任何一种数据处理框架绑定在一起,适配多种语言和组件。
格式布局
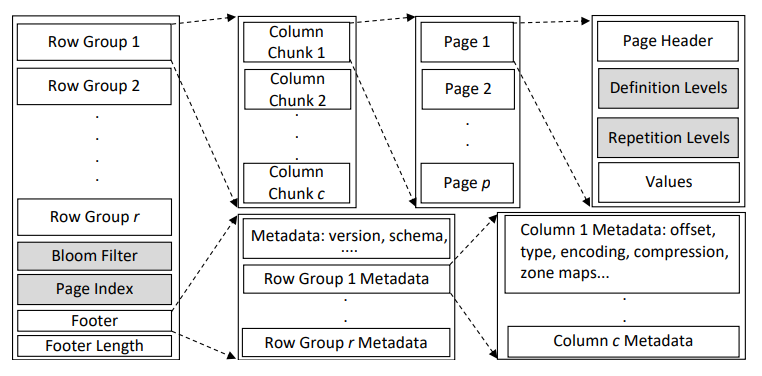
一个完整的Parquet文件包含数据和元数据信息。数据按行被切分为一到多个row group,每个row group中的每一列存储为一个连续的column chunk,每个column chunk切分为多个page。page是Parquet中的最小数据存储单元,一个page包含自身的元数据、实际数据值,和数据的嵌套层级信息。
Parquet将元数据放在文件末尾footer中,主要包含文件版本、schema,和每个row group中每个column chunk的位置、类型、编码方式、压缩方式、zone maps(page粒度统计指标,包含最大值、最小值、count)等信息。
为了提高查询效率,Parquet还支持额外的Bloom Filter结构。Bloom Filter是一种空间效率很高的概率数据结构,用于快速判断某个值是否存在。Parquet支持为每个column chunk创建Bloom Filter,当查询的选取值很少时,系统通过预先检查Bloom Filter从而快速判断查询值是否存在于该columns chunk中,不存在时直接跳过该column chunk。另外,元数据中的zone maps也可以起到类似的过滤作用。
类型系统
Parquet支持的物理类型(Physical Types)如下:
- BOOLEAN: 1 bit boolean
- INT32: 32 bit signed ints
- INT64: 64 bit signed ints
- INT96: 96 bit signed ints
- FLOAT: IEEE 32-bit floating point values
- DOUBLE: IEEE 64-bit floating point values
- BYTE_ARRAY: arbitrarily long byte arrays
- FIXED_LEN_BYTE_ARRAY: fixed length byte arrays
Parquet在设计上只定义了较少的物理类型,通过在物理类型上附加逻辑类型(Logical Types)来支持丰富的数据类型。比如,16位int实际上由int32支持;string类型会存储为UTF-8编码的byte_array;map、array等复杂类型通过组合多个物理类型来表示。
编码策略
Parquet对每个column chunk编码,并使用了压缩效率和读取效率都较好的编码策略:
-
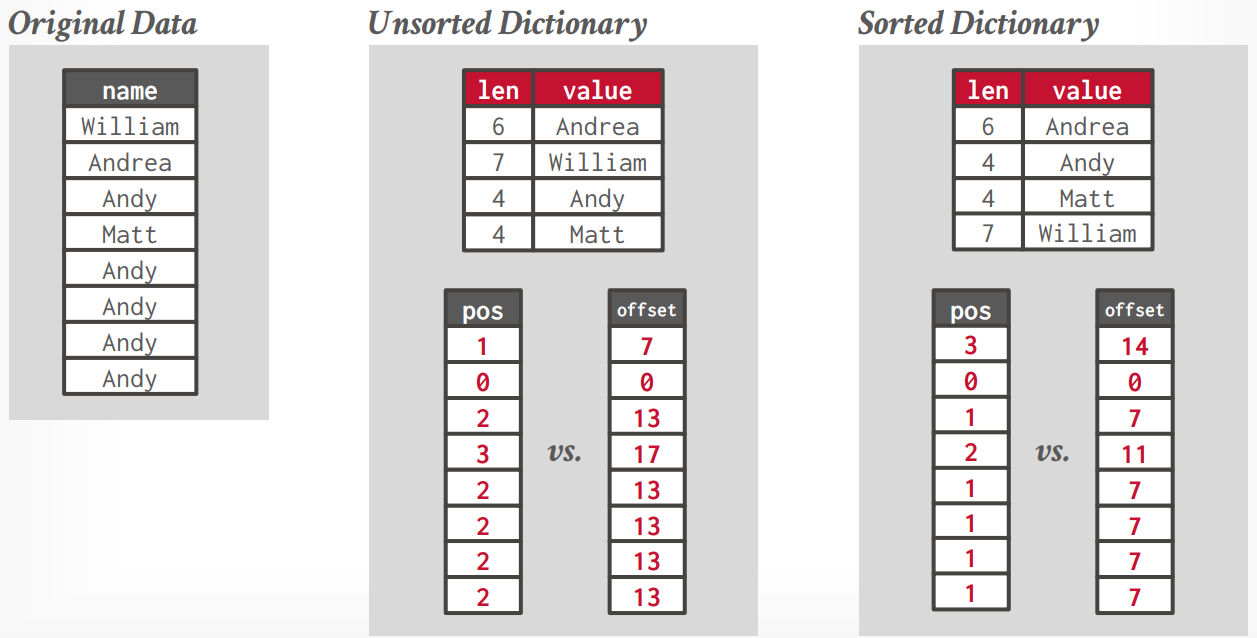
字典编码(Dictionary Encoding):Parquet在所有类型的列上都首先应用了字典编码。字典编码通过构建一个字典,将原始值替换为更易于存储的形式(如从0开始的整数),从而减少数据量。Parquet根据原始值的出现顺序构建字典,当字典超过容量阈值(默认1MB)时,后续数据不再使用字典编码,直接存储为原始值。字典编码特别适用于重复值较多的数据列。
-
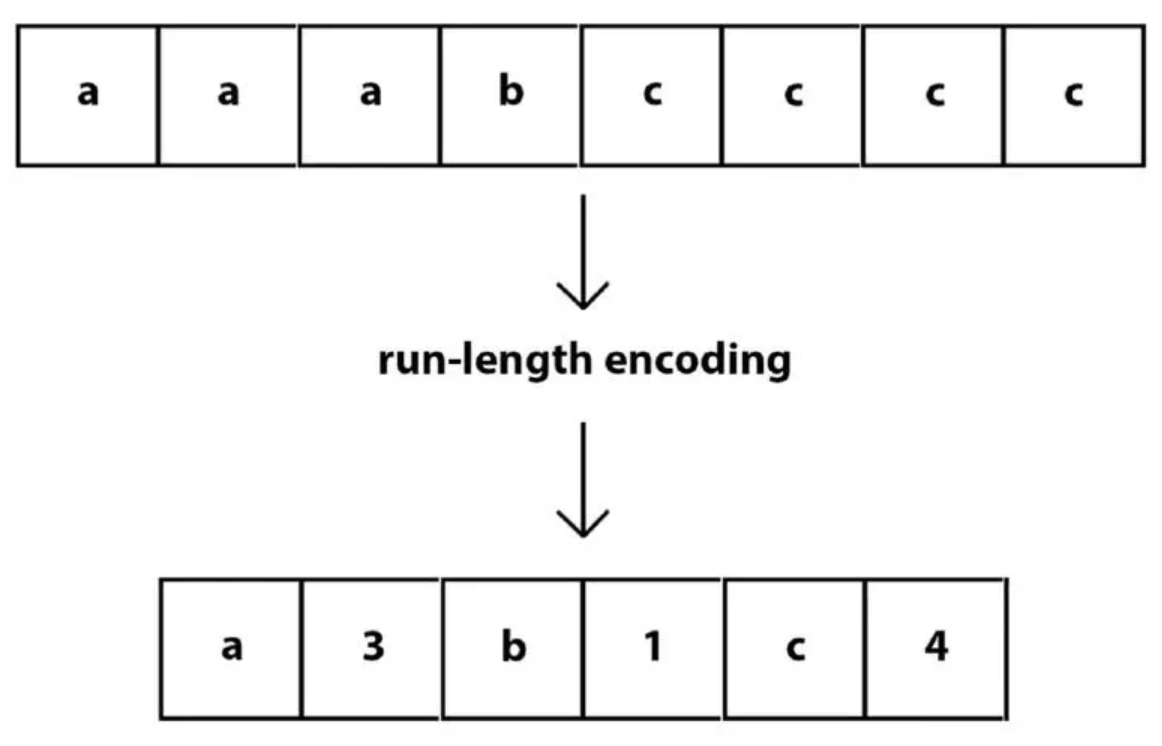
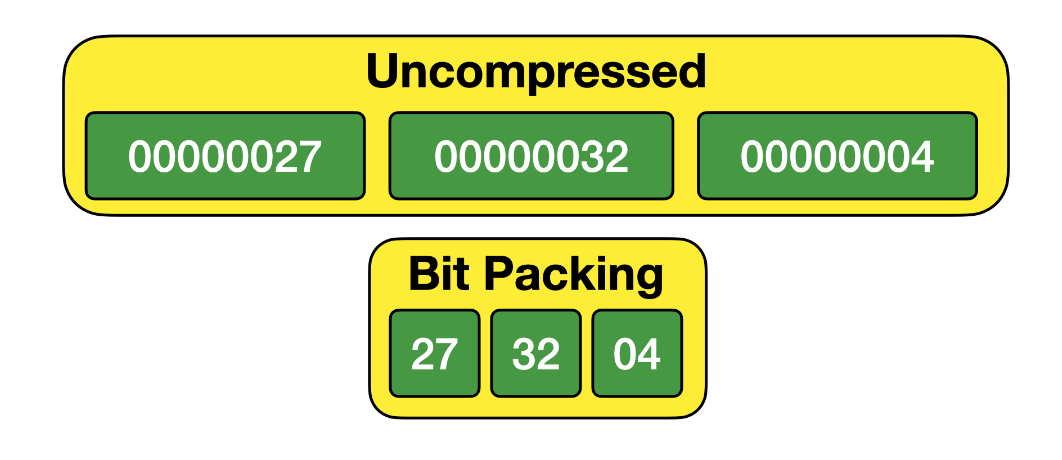
RLE+Bitpacking:Parquet对经过字典映射后的值再进一步编码。如果一个值连续重复出现8次或以上(该值目前不可配置),Parquet将使用RLE对该column chunk编码,否则使用Bitpacking。RLE(Run-Length Encoding)和Bitpacking算法示意图如下:
块压缩
块压缩对已编码column chunk做进一步压缩。虽然块压缩可以进一步减少文件大小,但现代存储系统的计算成本通常高于存储成本,块压缩的解压缩开销可能会超过存储节省带来的收益,因此是否使用块压缩取决于具体的使用场景。目前Parquet支持的压缩算法包括snappy、gzip、zstd。
嵌套结构
为了支持半结构化数据(如JSON或Protocol Buffers),Parquet实现了基于Dremel模型的嵌套数据处理方案。对于每个嵌套的字段,Dremel/Parquet对每个值添加两个额外的标识:重复层级(Repetition Levels, R)和定义层级(Definition Levels, D),目标是将嵌套数据按列拆开存储,并在读取时能够通过额外信息恢复出嵌套结构。这两个概念容易引起误解,此处直接引用Dremel论文的定义,下文在图例中详细说明:
- Repetition Levels: At what repeated field in the field’s path the value has repeated(在字段路径上的所有repeated字段中,当前字段值在第几层重复了)
- Definition Levels: How many fields in path that could be undefined (because they are optional or repeated) are actually present(在字段路径上的所有optional或repeated字段中,当前字段值在第几层有定义)
Dremel数据模型
Dremel模型对每个字段定义了required/optional/repeated属性,并允许嵌套字段。Required/optional/repeated属性规定的是该字段在其父节点下允许有值的数量。例如,下图的DocId是一个required字段,则值不能为null(父节点下有且只有1个值);Links可以为null,但一条记录中只会出现一次(父节点下有0或1个值);Backward和Forward可以在Links中出现零至多次(父节点下有0、1,或多个值),以此类推。
下图左侧是样例数据Document的原始形式(r1, r2)和schema,右侧是在Dremel/Parquet中的实际存储形式。原始数据的每个叶子字段在实际存储中单独存为一列,并加上层级标识。层级标识使得嵌套结构的字段会额外占用一些存储空间,但上文所述的编码策略可以对其进行有效压缩;没有嵌套结构的字段(如DocId)层级标识为0。
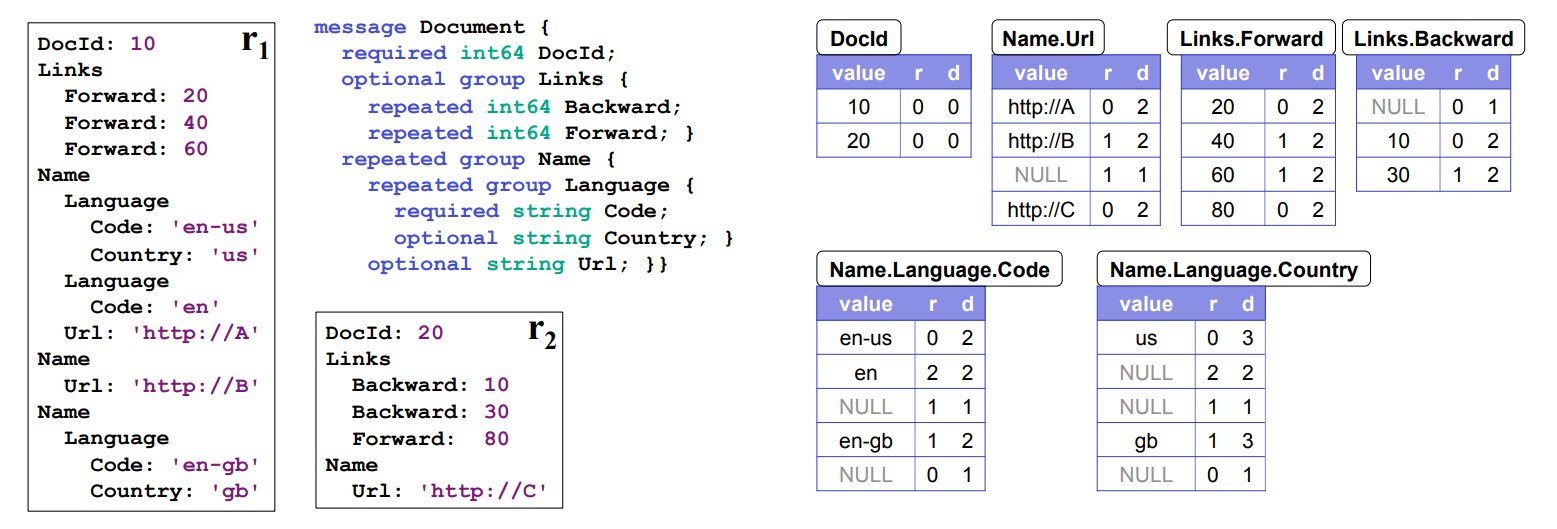
Repetition Levels
以样例数据Document的Code字段为例。Code字段完整路径为Name.Language.Code,其中有两个repeated字段Name(第1重复层)和Language(第2重复层),因此repetition level取值范围为{0,1,2}。系统对每个字段编码时,按顺序读取原始数据。读取到’en-us’时,Code在路径中Name、Language两个可重复的字段中都没有出现过,因此r取0;读取到’en’时,Code在Language层重复,因此r取2;下一个Name中不含Language,即Name.Language.Code值为null,此时仍然认为Code出现,并在Name层重复(用null占位,以免读取下一个’en-gb’时无法判断其属于哪个Name),因此r取1,以此类推。
Dremel模型可以用树状结构表示,而repetition leve可以理解为每个叶子节点(值)在哪一层上产生分支。如下图所示,level2(完整路径为level1.level2)字段的每个数据值a-j按顺序存储为一列,R为repetition level。R = 0时从第0层(根节点)开始产生分支,R = 1时从level1产生分支,以此类推。这样,读取实际存储的level2列时,系统通过R就可以知道将每一个值组装在树状结构的哪层分支上,从而恢复原始的嵌套结构。
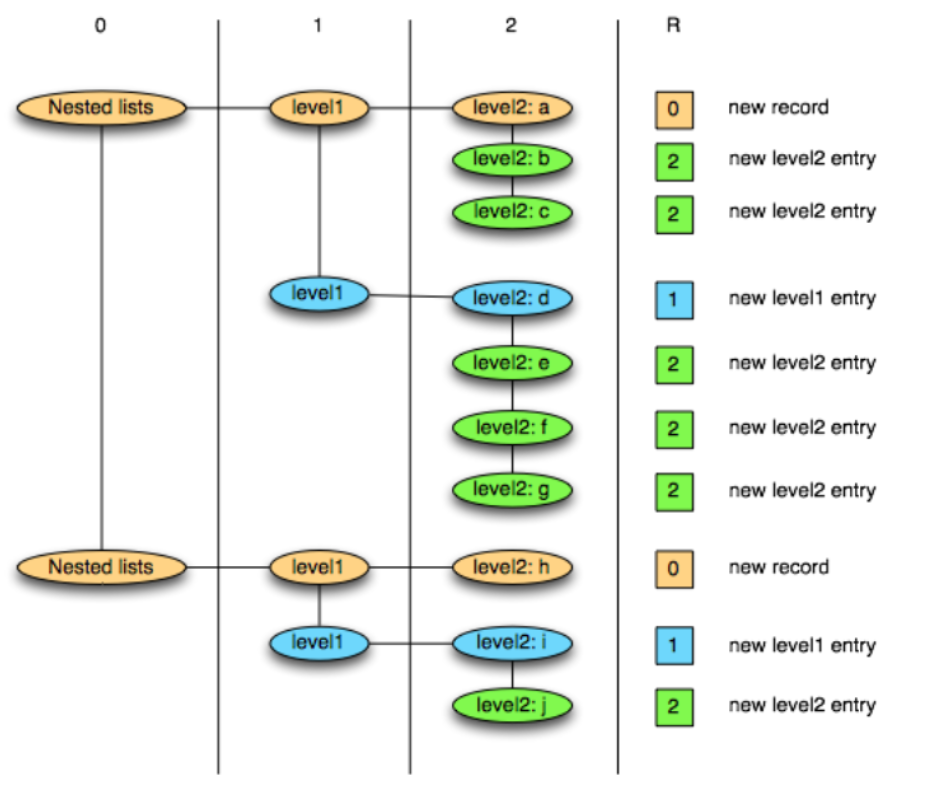
Definition Levels
由于Dremel模型允许optional字段,定义definition level使系统读取字段值时知道应组装在树状结构的哪一层。如下图最后一个分支,如a.b.c字段有值,由于路径上的a, b, c均为optional/repeated,则该记录definition level为3。
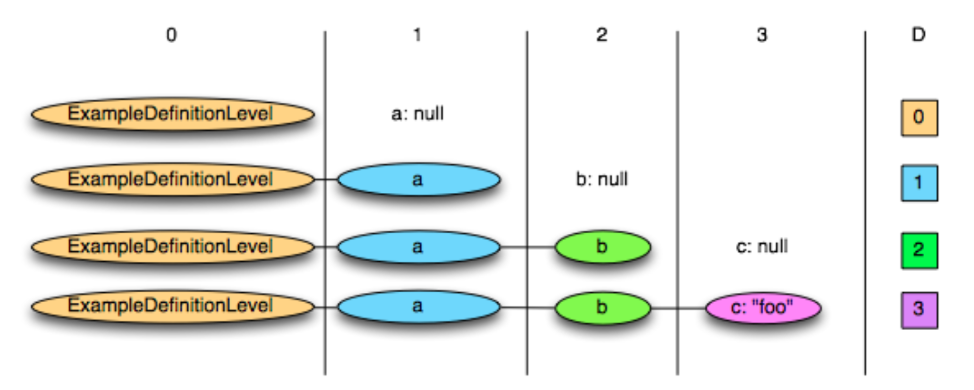
再以样例数据的Name.Language.Country为例,系统读取到’us’时,路径上三个可选字段Name, language, country均存在,因此d取3;读取到同一个Name的下一个Language时,只有Name, Language存在,因此d取2(与repetition level类似,用null值占位);读取到下一个Name时,只有Name存在,因此d取1。
组装算法
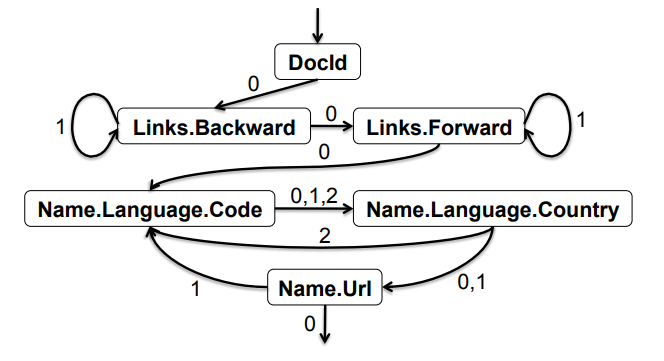
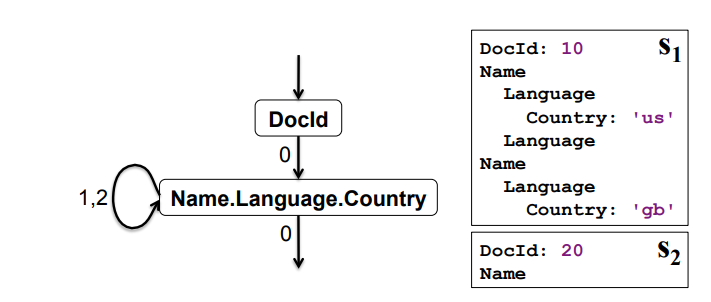
对Parquet格式的数据查询时,系统使用组装算法将列式存储恢复为原始结构。该算法根据字段结构和查询字段构造有限状态机(如下图第一张),然后按照状态机的遍历次序读取列式存储的表,结合levels信息组装出原始数据。仅读取指定字段时,可以构造更简单的状态机(如下图第二张),避免读取全部数据。例如,第二张的状态机表示:
- 从DocId表开始读取并组装DocId字段数据;
- DocId的level为0时,跳转至Name.Language.Country表,组装Country字段;
- 如repetition level为1或2,则表示数据在Name或Language层有重复,需继续使用Country表组装;如repetition level为0则完成本条记录组装,进入下一次循环。
参考资料
- Dremel: A Decade of Interactive SQL Analysis at Web Scale
- Dremel: Interactive Analysis of Web-Scale Datasets
- An Empirical Evaluation of Columnar Storage Formats
- https://blog.x.com/engineering/en_us/a/2013/dremel-made-simple-with-parquet
- https://parquet.apache.org/docs/
- https://www.infoq.cn/article/in-depth-analysis-of-parquet-column-storage-format/
- https://blog.csdn.net/macyang/article/details/8566105
- https://15721.courses.cs.cmu.edu/spring2024/notes/02-data1.pdf